This blog post go through the basics of point cloud data and related projects I have done, including point cloud registration, point cloud segmentation.
Basics of PCD
Point cloud data contains information of a set of points in three-dimensional space. Each point is represented as a vector of its 3D Cartesian coordinates (x, y, z), plus other information such as color (RGB), reflection intensity (Intensity) etc. Point cloud data can be acquired from LiDAR, RADAR, RGB-D cameras, or derived from images using multi-view stereo vision algorithms.
Point Cloud Registration
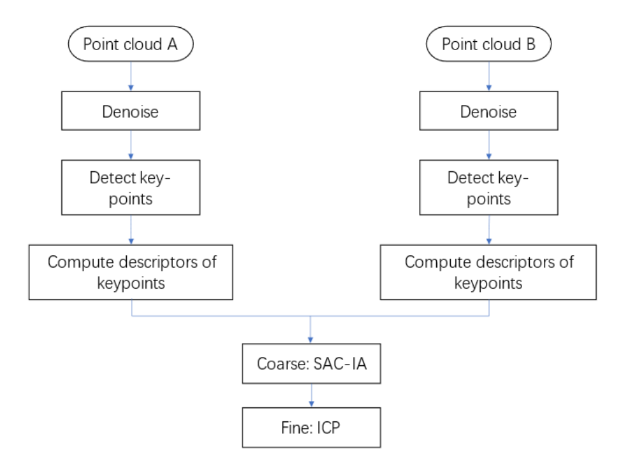
One of the base tasks in the applications of PCD is point cloud registration. The idea behind is to get the transformation information by matching adjacent point clouds, thus to ground the high level tasks such as state estimation of a moving robot. Matching two point clouds actually means finding the same set of points that shows in both point clouds and calculate the transformation matrix. However, it’s nontrivial to find the points consistent in two point clouds. There are many sophisticated hand crafted descriptors to help find similar points in two point clouds, deep learning based methods are also on the table.
Point Cloud Segmentation
Point cloud segmentation is a classic task to cluster points with similar characteristics into homogeneous regions. Point cloud semantic segmentation takes a step further, aim to assign each 3D point a semantic label. After many explorations in supervised machine learning methods including Support Vector Machine, Gaussian Mixture Model, Random Forest and statistical contextual models, such as Conditional Random Field, deep learning based methods now achieve the state of the art for point cloud segmentation. Instance segmentation achieves detection and semantic segmentation of objects at the same time, by giving different labels for separate instances belonging to the same class. If we predict background semantics while doing instance segmentation, we get panoptic segmentation, the goal of which is to assign each point (pixel for images) a semantic label and instance ID if the point belongs to an object. Then if we can track objects moving in a sequence of consecutive point clouds and conduct the panoptic segmentation on every point cloud, we obtain a 4D panotic segmentation (3D space and 1D time).
Facilitated by the development of deep learning in subfields of computer vision including single object tracking (SOT), video object detection (VOD), and re-identification (Re-ID), many methods of multi-object tracking (MOT) have emerged, such as various embedding models designed for object locations and track identities [1]. While tracking-by-detection is still an effective paradigm for MOT, since we can always combine off-the-shelf state-of-the-art detectors and Re-ID models to improve the MOT system. The idea is: detect the objects in the current frame, then try to associate the detected boxes with tracked boxes in the previous frames. In practice, we need a more sophisticated design (e.g. choose similarity indices for data association, use Kalman Filter to predict new locations of tracks etc.) and proper strategies (e.g. to delete or initialize tracks). Hunarian algorithm is commonly used to matching objects after we get the similarity matrix, in this blog, I will try to explain how and why Hunarian algorithm works from the perspective of linear programming.
Problem Description
Hunarian algorithm or Kuhn-Munkres algorithm is well known for solving assignment problem, which involves assigning tasks to agents (or jobs to workers) such that the total cost is minimized (or the total profit is maximized), subject to the constraint that each agent is assigned exactly one task, and each task is assigned to exactly one agent.
Primal Form of the Assignment Problem
We are given an $n \times n$ cost matrix $C$, where $c_{ij}$ is the cost of assigning agent $i$ to task $j$. \(\begin{aligned} \text{min} & \sum_{i \in I} \sum_{j \in J} c_{ij}x_{ij} \\ s.t. & \sum_{j \in J}x_{ij} = 1 \text{ for all } i \in I \\ &\sum_{i \in I}x_{ij} = 1 \text{ for all } j \in J \\ & x_{ij} \geq 0 \end{aligned}\)
Note that $x_{ij} = 1$ if i is assigned to j and 0 otherwise.
Assignment Problem is a classic linear programming problem, since both the objective function and constraints are linear sums, even though it involves binary decision variables. We can model the problem as a bipartite graph and interpret the algorithm from the perspective of graph (find the perfect matching by finding augmenting path), but this blog will not cover this topic. Let’s try to understand Hungarian algorithm under the framework of linear programming. Since the primal problem is tricky to deal with, let’s go for the dual form of the problem.
Primal to Dual To convert the primal Assignment Problem to its dual form, we need to use Lagrange multipliers to relax the equality constraints in the primal problem. Introduce $u_i$ as the Lagrange multiplier associated with the constraint that agent $i$ is assigned exactly one task ($\sum_j x_{ij} = 1$), $v_j$ as the Lagrange multiplier associated with the constraint that task $j$ is assigned to exactly one agent ($\sum_i x_{ij} = 1$), then formulate the Lagrangian: $$ L(x_{ij},u_i,v_j)=\sum_{i=1}^n \sum_{j=1}^n c_{ij}x_{ij}+\sum_{i=1}^n u_i (1-\sum_{j=1}^n x_{ij})+\sum_{j=1}^n v_j (1-\sum_{i=1}^n x_{ij}) $$ Lagrange dual function is defined as the minimum value of the Lagrangian over primal variables: $$ g(u,v)=\text{inf}_x L(x,u,v) $$ where $\text{inf}_x$ means the infimum (the lower bound) of the Lagrangian over $x$. Since the dual function is the pointwise infimum of a family of affine functions of (u, ν), it is concave, even when the problem is not convex [2]. To minimize this Lagrangian $L(x_{ij},u_i,v_j)$ with respect to $x_{ij}$, rewrite the Lagrangian as: $$ L(x_{ij},u_i,v_j)=\sum_{i=1}^n \sum_{j=1}^n [(c_{ij}-u_i-v_j)x_{ij}] + \sum_{i=1}^n u_i + \sum_{j=1}^n v_j $$ The minimization occurs in the condition: $$ x_{ij}=1 \ \text{ if }\ c_{ij} \leq u_i+v_j \\ x_{ij}=0 \ \text{ if }\ c_{ij} > u_i+v_j $$ Now we want to find the tightest lower bound or minimum duality gap, so we need to maximize the dual function w.r.t $u$ and $v$. In the case of $x_{ij}=1$ If $c_{ij} \leq u_i+v_j$, the maximum occurs when $c_{ij} = u_i+v_j$, so $c_{ij}-u_i-v_j$ in Lagrangian is non-negative.
Dual Form of the Assignment Problem
The dual form of the Assignment Problem can be written as: \(\begin{aligned} \text{max} &\sum_{i=1}^n u_i + \sum_{j=1}^n v_j \\ s.t. & u_i+v_j \leq c_{ij}, \ \forall i, j \end{aligned}\)
where $u_i$ is the dual variable associated with agent $i$’s assignment constraint, $v_j$ is the dual variable associated with task $j$’s assignment constraint. The strong duality theorem of linear programming guarantees that if a feasible and bounded solution exists for the primal linear problem, the dual linear problem is feasible (and bounded as well, by weak duality), with the same optimum value as the primal [3]. The primal problem has constraints that ensure every agent is assigned exactly one task, and every task is assigned exactly one agent, a feasible primal solution exists (since the problem is well-posed with the same number of agents and tasks).
Hungarian Algorithm
Given a $n \times n$ cost matrix (Adjacent Matrix in Graph theory) $C$, the algorithm is summarized as 5 steps below:
Find and subtract the row minimum, namely find the minimum element in each row of the cost matrix and subtract the minimum element in each row from the element in that row.
Find and subtract the colume minimum, namely find the minimum element of each column in the remaining matrix and subtract the minimum element in each column from the elements in that column.
Use the minimum number of horizontal or vertical lines to cover all zero elements in the matrix. If the minimum number of lines is equal to $n$, stop running; if the minimum number of lines is less than $n$, continue to the next step.
Find the minimum value among the uncovered elements, subtract this minimum value from the uncovered elements, and add this minimum value to the elements at the intersection of different lines.
Go back to step 3, that is, continue to cover all zero elements in the matrix with the minimum number of horizontal or vertical lines. If the minimum number of lines is equal to $n$, stop running; if the minimum number of lines is less than $n$, execute step 4.
For details of $O(n^3)$ algorithm implementation, refer to this blog from cp algorithms, where the dual variables $u,v$ are denoted as potential. Hungarian algorithm updates the search of optimal value by continuesly increase the sum of $u,v$: \(f= \sum_{i=1}^n u[i] + \sum_{j=1}^n v[j]\)
In the context of MOT, cost matrix is filled with IOU or similarity score obtained from ReID features between objects in two consecutive frames. Sometimes the matrix is non-square, we can add dummy rows or columes with zeros and run more iterations.
Reference: [1] Wang, G., Song, M., & Hwang, J. N. (2022). Recent advances in embedding methods for multi-object tracking: a survey. arXiv preprint arXiv:2205.10766. [2] Boyd, Stephen, and Lieven Vandenberghe. Convex optimization. Cambridge university press, 2004. [3] Matoušek, Jiří, and Bernd Gärtner. Understanding and using linear programming. Vol. 1. Berlin: Springer, 2007.
In this blog, I’m going to share how I deployed LLMs (1~3b) and ASR models (whisper tiny & base) on my old smart phone, Xiaomi 8 (dipper). It was released in 2018, with a broken screen and depleted battery after several years of heavy usage, it still offers acceptable speed and fluency running daily light-weight apps. So I wonder, if I deploy modern machine models, such as LLMs, on the phone, and can I run the large models smoothly. Let’s see. The hardware configuration: 8-cores CPU with 4 big cores (Cortex-A75) and 4 small cores (Cortex-A55), 64 GB storage and 6 GB RAM. It has a integrated GPU, which I didn’t find a way to utilize during model inference, so the computation is totally counted on CPU in this trial. To better leverage the power of this CPU, I uninstall the android system (MIUI 12) and port a Ubuntu touch on the phone. Basically it’s a linux OS but using the underlying andriod framework to control hardwares, and it gives me a much longer battery life compared to android, also more convenience since I am a rookie in android development. Models are quantized versions from llamacpp and whispercpp. To get rid of the cumbersome work build an app with GUI, I run models in command line using the terminal app originally from Ubuntu touch, which can be regarded as the same terminal on Ubuntu desktop in this case. All I need to do is to compile the c++ code into an executable file that runs on my phone. Since the architecture of my laptop cpu is x86, the version of glibc, libstdc++ are different from the libs on the phone, I could either compile on the phone directly or cross compile on my PC with a specific toolchain. I kept all the heavy work on PC and built my own toolchain using crosstool-NG, which is targeted at building toolchains.
Large Language Models (LLMs) have revolutionized the field of natural language processing, enabling significant advancements in tasks such as language translation, text summarization, and sentiment analysis. However, despite their impressive capabilities, LLMs are not without limitations. One of the most significant challenges facing LLMs today is the problem of inference speed. Due to the sheer size and complexity of these models, the process of making predictions or extracting information from them can be computationally expensive and time-consuming. Several ways to speed up the LLMs without updating hardware:
Large Language Models (LLMs) are the brains of various chatbots, and luckily we all have access to some brilliant cheap or even free LLMs now, thanks to open source community. It is possible to run LLMs on a PC and keep everything local. This blog presents my solution to building a chatbot running on my PC, with a totally local file storage system and a costumized graphical user interface.