This blog records how I explored building a personal AI assistant step by step, integrating ASR and TTS modules into LLM and deploying them on PC and mobile phones.
Build a local chatbot using langchain Link to heading
Large Language Models (LLM) have surprised us in many ways, such as talking like human, processing paper work, codeing copilot, analyzing data…, simply by predicting the next token using probability model. As the LLMs get smarter and lighter, we can leverage LLMs that are close to or even surpasse the capabilities of ChatGPT on our device, which is going to make our life much easier. This blog shows how to build a chatbot that runs 100% locally and shares my thoughts on how the LLMs can help in our daily life.
Model Link to heading
Let’s choose a LLM first. There are a lot of LLMs available on huggingface, we have to pick one that our local device can handle. Thanks to LLamacpp, people that cannot afford an professinal graphics card (me included) have a chance to play with different open sourced LLMs. For example, I choose vicuna-13b-4bit-ggml, which belongs to Llamma model family and is a 4bit quantized version in ggml format (official format in llamacpp). Now it’s time to dive into the technical part.
Langchain Link to heading
To get a chatbot, we need some extra seasoning since what the raw LLM can do is to predict the next word based on your input prompt. Langchain offers modular components and off-the-shelf chains to harness the LLM to complete high level tasks, including adding memory to our chatbot, enabling the chatbot to retrieve useful information from different sources. Don’t be intimidated by the complex concepts, I will show you how to build a chatbot step by step.
Prompt Template
A prompt template is a way to provide additional context and instructions to a language model. It allows the user to input specific information that will be incorporated into the generated text. The template consists of a prompt that includes variables, which will be filled in with user input. A template for a chatbot looks like this:
template = '''You are an AI chatbot having a conversation with a human.
{history}
Human: {input}
Chatbot:'''
Conversation Memory
As mentioned above, chatbot needs to remember the history as the chat goes on. The simplest way is to save the history into a buffer and combine the history and current prompt as the whole prompt input into the LLM. Langchain wraps this up and provides multiple classes of memory for various use. Take 'ConversationBufferMemory' for instance, it keeps a buffer of all prior messages in a conversation which can be extracted as a string or as a list of messages. More advanced option is ConversationSummaryMemory, which stores condensed information summarized by LLM from conversation history, thus it captures and utilizes important information for a more sophisticated conversation experience.
Now let's combine LLM, prompt temlate and memory together, or 'chain them up', by using chain, the core value langchain provides. There are many chains available, I encourage you to try and find the best for you. Here I use 'ConversationChain' by simply pass the elements I want to combine:
conversation_chain = ConversationChain(llm=llm,prompt=prompt,memory=chat_Memory())
response = conversation_chain({'input': user_question})
That’s the backbone of a chatbot, you can put them in a while loop and start your conversation in terminal. But it’s nice to have an interface like ChatGPT webpage. In case that you don’t have experience in building website, Streamlit is an option to fast build a web app.
Customize a local chatbot in streamlit Link to heading
Large Language Models (LLMs) are the brains of various chatbots, and luckily we all have access to some brilliant cheap or even free LLMs now, thanks to open source community. It is possible to run LLMs on a PC and keep everything local. This blog presents my solution to building a chatbot running on my PC, with a totally local file storage system and a costumized graphical user interface.
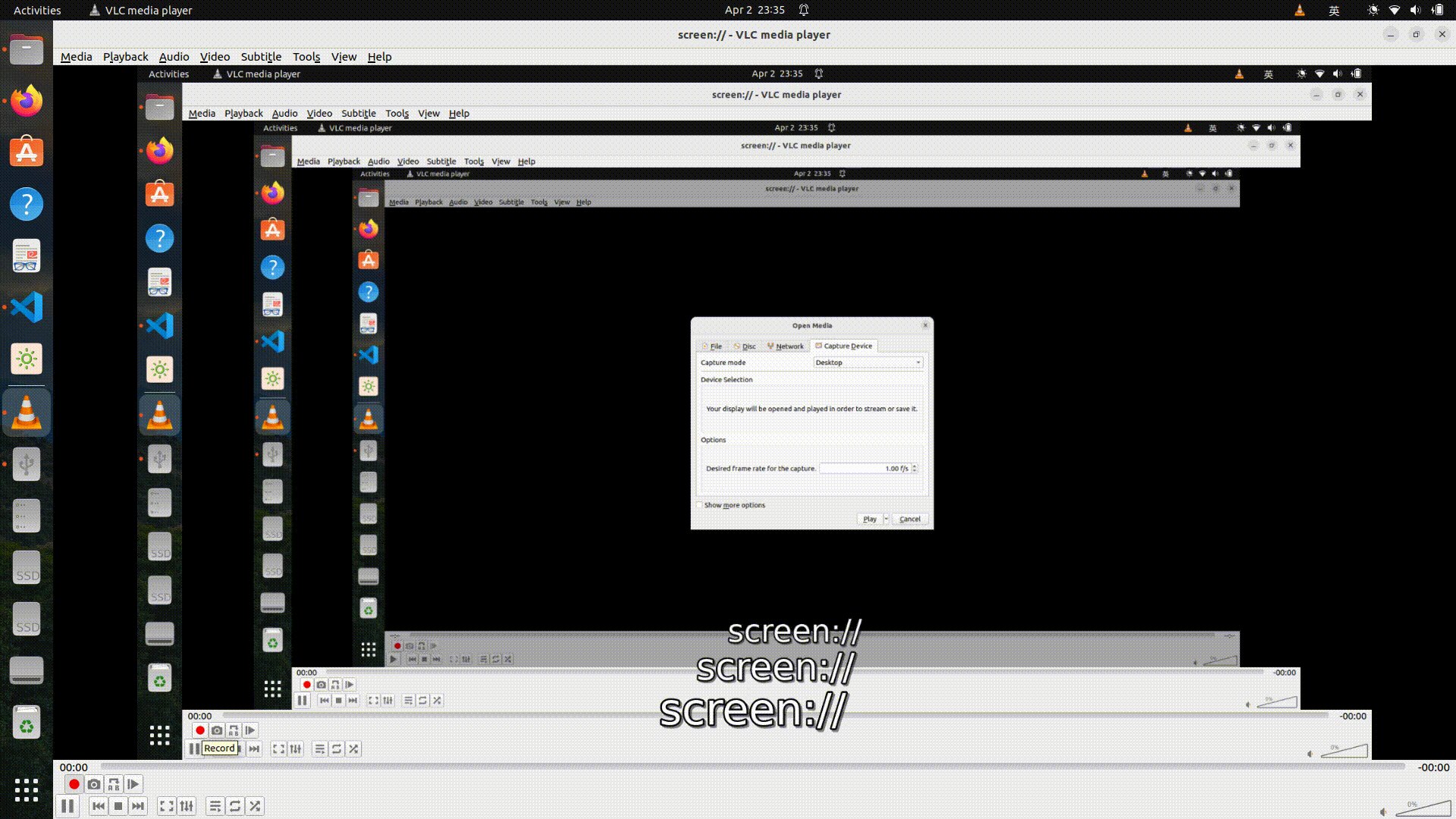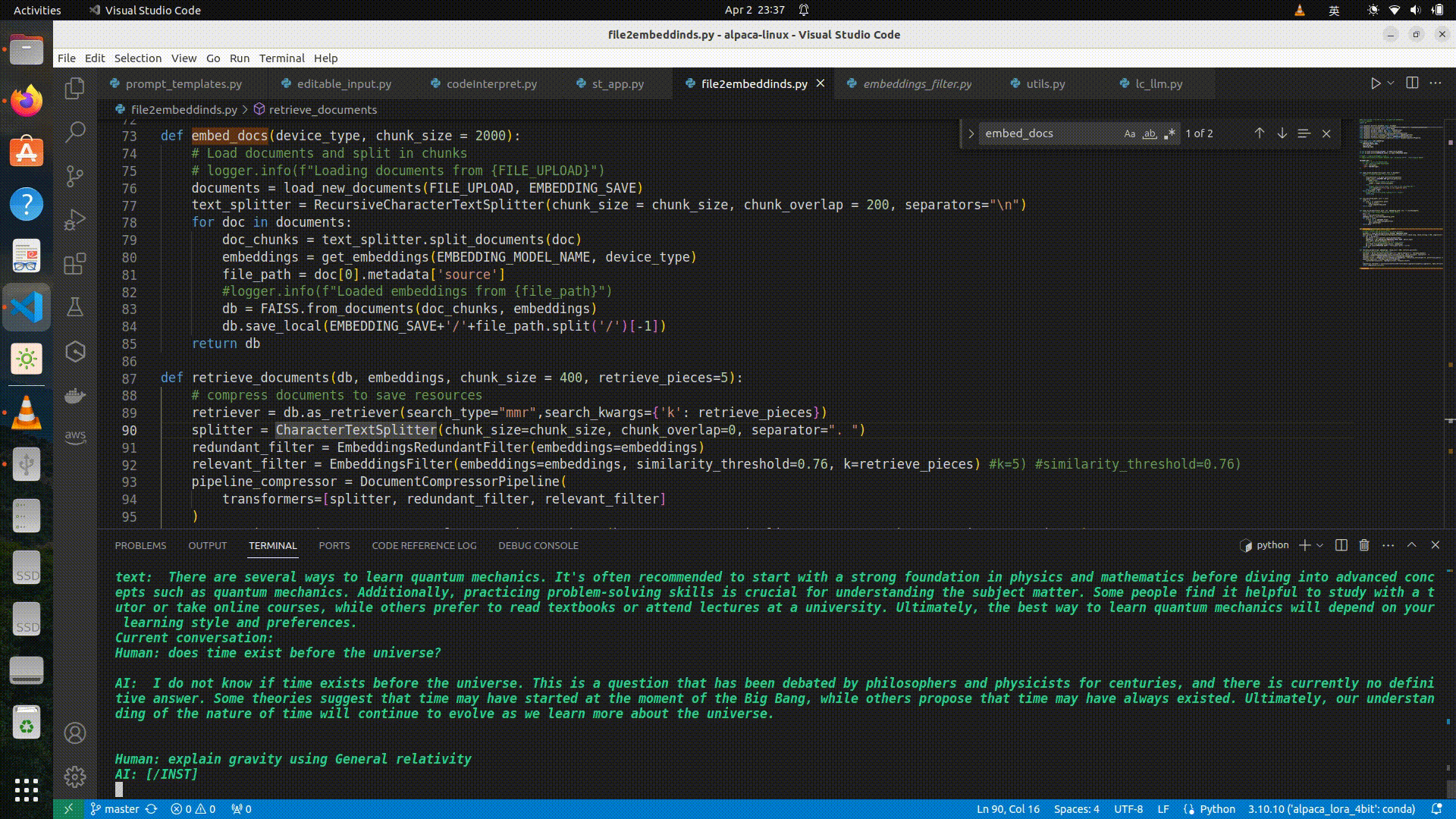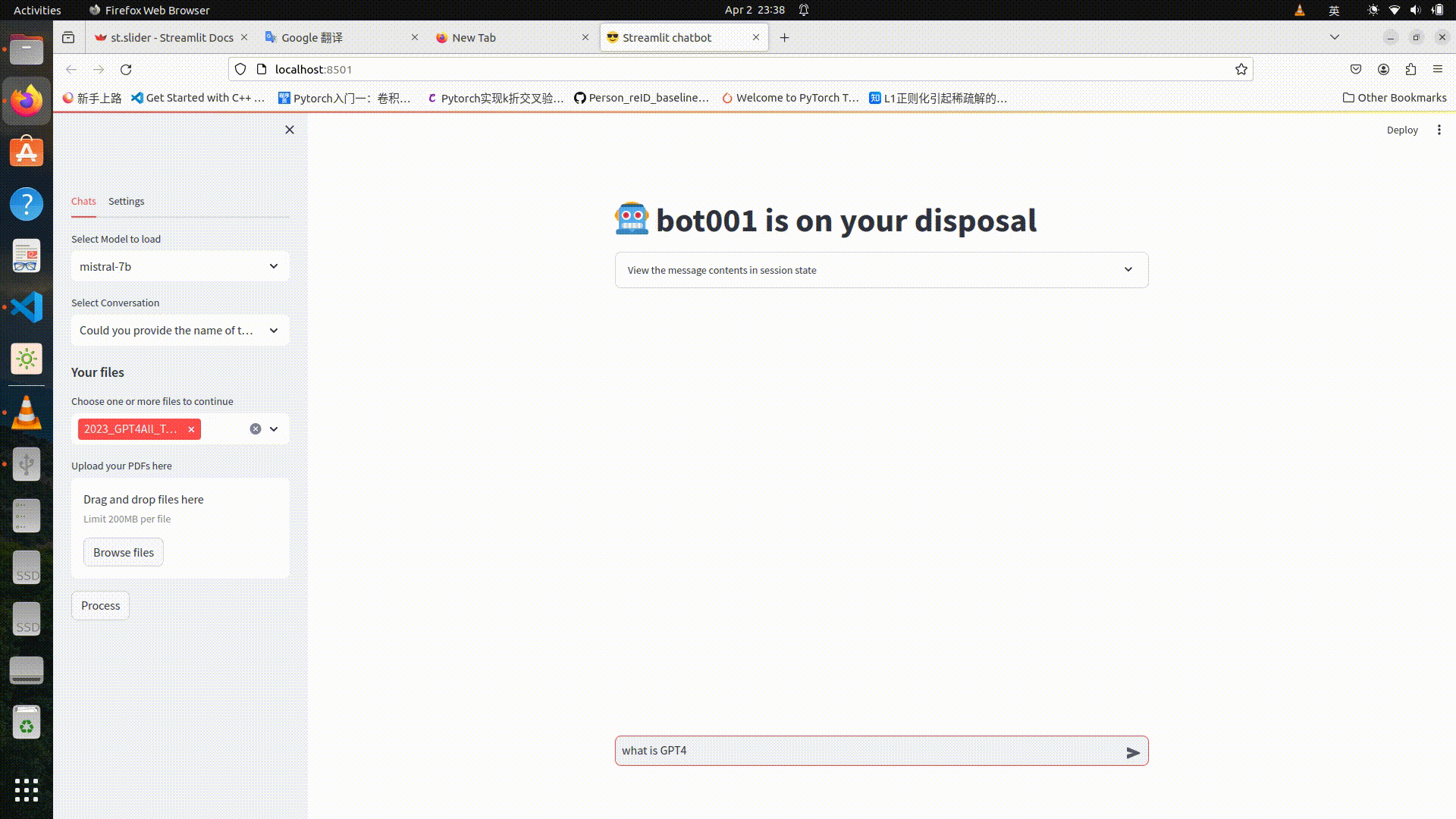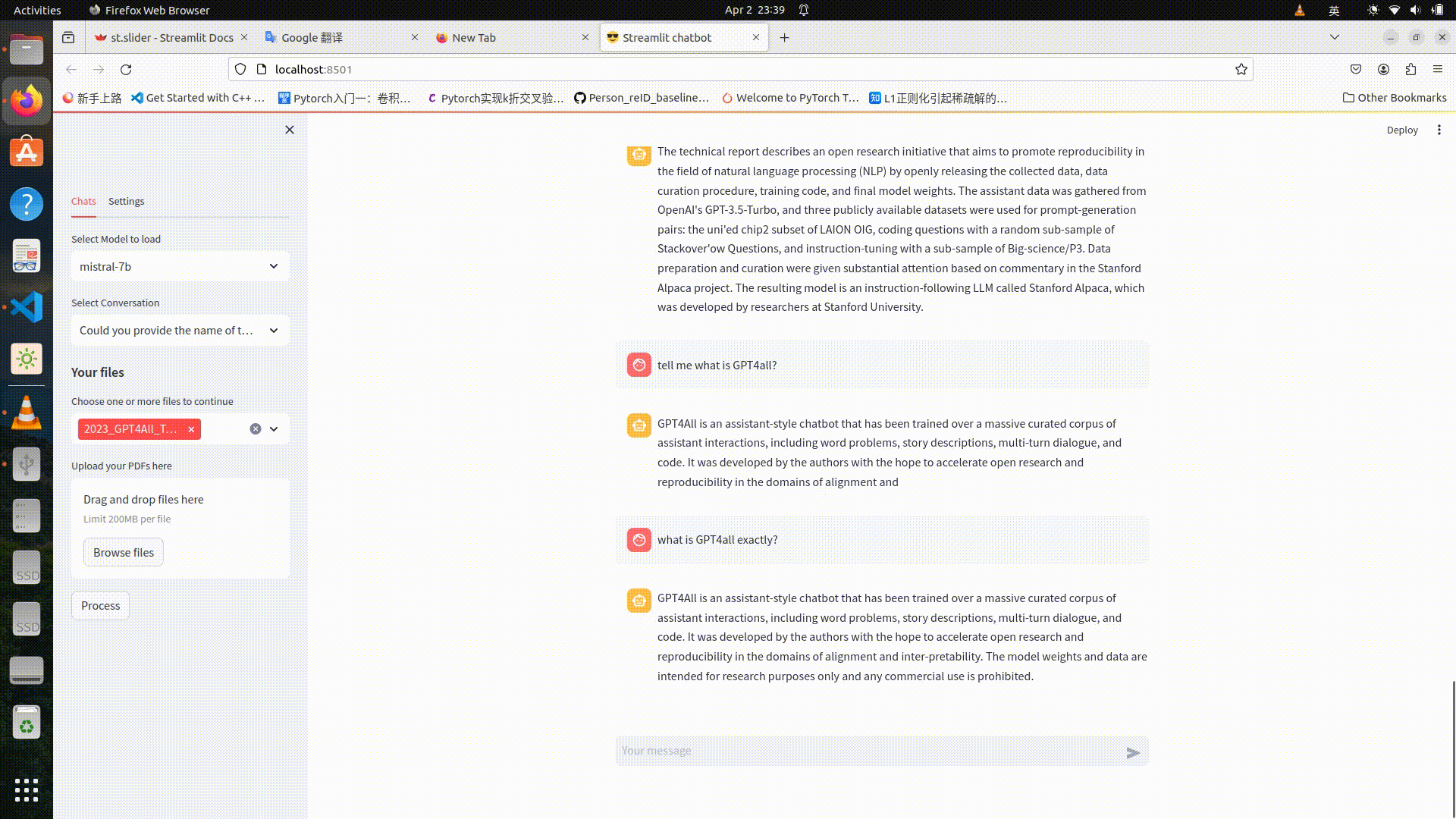
Considering that my 4-year old laptop has 16 RAM and 4GB VRAM, I choose quantized LLMs from llamacpp. Both gradio and streamlit are sufficient for fast prototyping, I use streamlit just because I think the app GUI looks better. To build a streamlit app, one must deal with session state, which stores variables across reruns and can be manipulated by callback functions. For example, we need to store a LLM in memory when chatting, otherwise everytime you rerun the app, you have to reload the LLM. Streamlit reruns the script when an interaction happens, and loading a LLM takes few seconds meanwhile occupies memory.
Loading LLMs Link to heading
I want to choose one to use from a list of LLMs, and may switch between different LLMs during chatting. Normally load a LLM in llama-cpp-python looks like:
CLICK ME
llm = LlamaCpp(model_path=llm_path,
n_threads=n_threads,
max_tokens=1024,
n_ctx=n_ctx,
n_batch=256,
n_gpu_layers=n_gpu, # if offload GPU
callback_manager=CallbackManager)
First initialize llm in session state, list all of the available LLMs in a selection box and match model to load:
if "llm" not in st.session_state: st.session_state.llm=None
models_list = ('-','codellama-13b', 'code209k_13b', 'mistral-7b', 'zephyr-7b','solar-10.7b','dolphin_7b')
selected_model = st.selectbox("Select Model to load", models_list,index=0,on_change=_clear_ram)
if st.session_state.llm is None:
match selected_model:
case 'codellama-13b':
st.session_state.llm = load_llm(CODELLAMA_13b,chat_box,10240,3)
case 'mistral-7b':
st.session_state.llm = load_llm(MISTRAL_7b,chat_box, 2048, 15)
Here load_llm is a wrapper of LlamaCpp, _clear_ram is a callback function, called when selection changes, to clear LLM in memory:
def _clear_ram():
del st.session_state.llm
gc.collect()
torch.cuda.empty_cache()
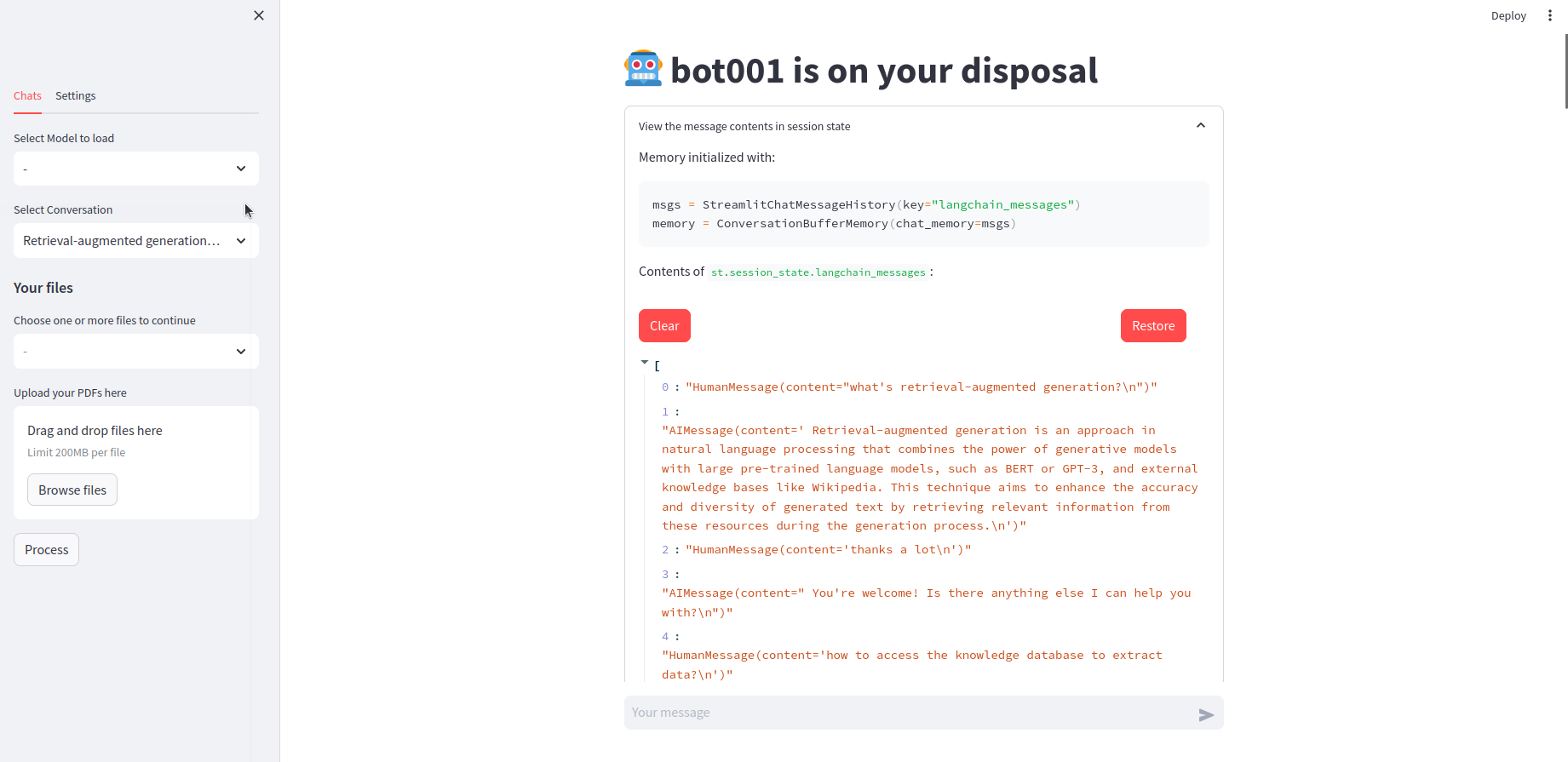
Restore and clean chat history Link to heading
After setting up LLMchains, the chatbot is ready to go. While I want to keep the chat history in case that I want to continue the chat some other day, I save all history in txt files ordered by the time they are generated, and set a select box to choose which chat to continue. To recognize the chats easier, I name these txt files after the content of the first question, summarized by LLMs.
Moreover, facilitated by vector similarity search, I use VectorStoreRetrieverMemory to enhance the chatbot, so it only remembers pieces of history that relevant to the input question. It’s optional to decide whether or not to remember the chat history, click clear to remove chat history from memory and save current memory as history, click restore to show the history on screen.
Chat over documents Link to heading
Aided by retrieval-augmented generation (RAG), it is possible for a local chatbot to read documents within an acceptable time period. Langchain provides a loads of file loaders, but more work need to be done in practice, for example, one may use some preprocessing tools to preserve the format of content read from a pdf file, or the pdf is a not standard pdf but a scanned pdf consists of images, extracting the content might be tricky (I use ocrmypdf to first transform the scanned pdf to a regular pdf, then put it into libraries like pymupdf). Here’s an example of contextual compression in langchain, which I use to filter relevant context for retrieved texts when I start a q&a over documents with the chatbot.
retriever = db.as_retriever(search_type="mmr",search_kwargs={'k': retrieve_pieces})
splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=0, separator=". ")
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76, k=retrieve_pieces)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(base_compressor=pipeline_compressor, base_retriever=retriever)
Extra tips Link to heading
If you set ‘callback’ when loading LLMs, you would see the LLMs’ output popping up in a terminal. To achieve the same popping ups in streamlit apps, I modified the CallbackHandler by adding a streamlit container:
class StreamHandler(BaseCallbackHandler):
def __init__(self, container, initial_text=""):
self.container = container
self.text = ""
def on_llm_new_token(self, token: str, **kwargs) -> None:
sys.stdout.write(token)
sys.stdout.flush()
self.text += token
self.container.markdown(self.text)
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
self.text = ""
Although I build this for local uses, you can easily add other online LLMs such as GPT3.5 or GPT4, the GUI and file system remains the same. I will add more functions like presenting the retrieved pieces of documents before sending to openai, to save money and gain more control.
Deploy LLMs on a phone with arm chips Link to heading
I have also combined Automatic Speech Recognition (ASR) and Text to Speech (TTS) with chatbot on my laptop, it works fine but not flexible enough. In this section, I’m going to share how I deployed LLMs (1~3b) and ASR models (whisper tiny & base) on my old smart phone, Xiaomi 8 (dipper). It was released in 2018, with a broken screen and depleted battery after several years of heavy usage, it still offers acceptable speed and fluency running daily light-weight apps. So I wonder, if I deploy modern machine models, such as LLMs, on the phone, and can I run the large models smoothly.
The hardware configuration: 8-cores CPU with 4 big cores (Cortex-A75) and 4 small cores (Cortex-A55), 64 GB storage and 6 GB RAM. It has a integrated GPU, which I didn’t find a way to utilize during model inference, so the computation is totally counted on CPU in this trial. To better leverage the power of this CPU, I uninstall the android system (MIUI 12) and port a Ubuntu touch on the phone. Basically it’s a linux OS but using the underlying andriod framework to control hardwares, and it gives me a much longer battery life compared to android, also more convenience since I am a rookie in android development. Models are quantized versions from llamacpp and whispercpp.
To get rid of the cumbersome work build an app with GUI, I run models in command line using the terminal app originally from Ubuntu touch, which can be regarded as the same terminal on Ubuntu desktop in this case. All I need to do is to compile the c++ code into an executable file that runs on my phone. Since the architecture of my laptop cpu is x86, the version of glibc, libstdc++ are different from the libs on the phone, I could either compile on the phone directly or cross compile on my PC with a specific toolchain. I kept all the heavy work on PC and built my own toolchain using crosstool-NG, which is targeted at building toolchains.
Following the offical tutorial, I set the version of glibc and libstdc++ according to my phone configuration, while the version of gcc is chosen based on the target code to build, in my case I use gcc 8.5. The version of libstdc++.so.6.0.25 comes with gcc8.5 is not aligned with the libstdc++.so.6.0.21 on my phone, a simple way to address this problem is upgrading old libstdc++ (just replace libstdc++.so could work). I also tried other methods such as building the project in a docker container from clickable (commonly used for deploying applications on ubuntu touch) with a old version of gcc (gcc5.4), I have to define the data types such as ‘vld1q_s16_x2’ manually since these are new types introduced in arm_neon.h in later gcc versions. Anyway, solving problems poping up during cross compiling helps me understand the code and computer system better, and finally I managed to get executable files from both llamacpp and whispercpp. After playing models of different sizes on the phone, I found that the model under 3b (quantized gguf) could achieve balance between speed and performance. I have tried Phi series models from Microsoft and stablelm (1.6b, 3b) from stabilityai, among which phi3 mini (4bit) is the largest one and gives best responses, but the speed is quite slow (1 token/s for prompt evaluation and 3 token/s for generation). The smallest one, stablelm 1.6b (4bit) yeilds 12 token/s and 7 token/s for prompt evaluation and generation respectively, while maintains a good generation quality. For daily use, I prefer this version of stablelm 1.6b, which gives better response after finetuning, with pleasent speed (10 token/s and 6 token/s) at the same time.
I also built piper from source, in which case piper-phonemize must be built in advance. There are built binary releases avaliable for aarch64 or arm, but none of them were built under the same old version of linux kernel and glibc as I have on my phone. Another thread related bug arose when I was naively combining piper with llamacpp (run piper everytime the LLM completed a response), I set the number of thread to 1 when loading piper mode (SetInterOpNumThreads) to avoid the error. Then a voice assistant is ready to serve.
This project proves that my a 6-year old phone is sufficient to run modern machine learning models after optimization, I will try to test image processing on my phone by running some famous models in computer vision.