In this post, I’ll walk through a concrete case: building a local agent with retrieval, tool use from both local and mcp server, focus on designing RAG pipeline and context engineering, and trade-offs in these decision makings. I use it mainly for q&a over papers, webpages and books now. The code is available on git.
Architecture Link to heading
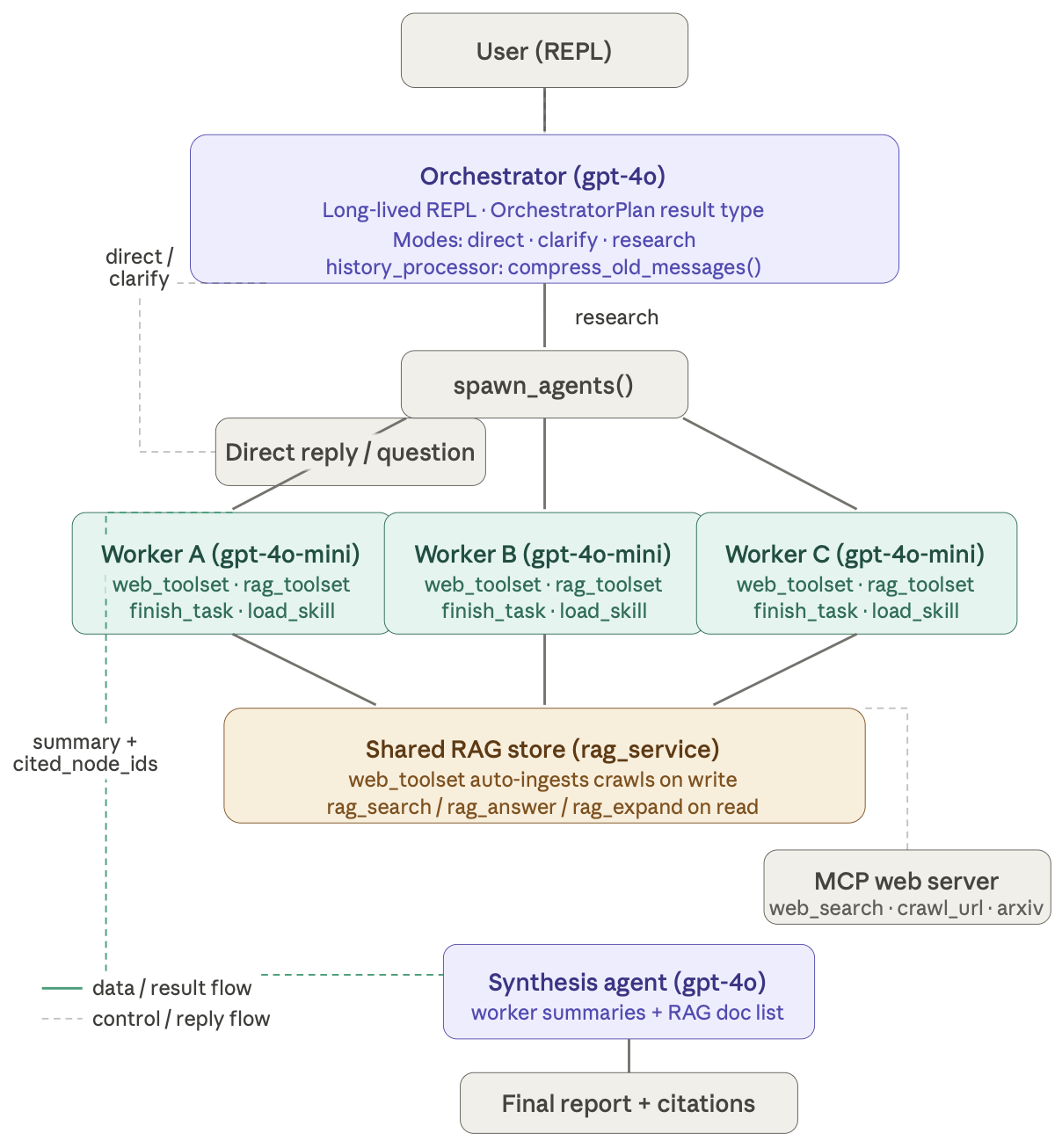
This is AI generated image, the numbers are not the ones used in practice, and in this post, gpt-4o refers to larger LLM within the budget, gpt-4o-mini refers to a smaller LLM.
The system has two tiers. The orchestrator is a long-lived conversational agent — the thing the user actually talks to across an entire session. On every turn it chooses a mode (or A router agent for mode selection): answer directly (optionally searching the web), ask a clarifying question, or decompose the request into parallel research subtasks and delegate. The workers are stateless, short-lived, and cheap — each one owns a single research objective, runs it to completion, and hands back a plain-language summary plus a list of source IDs traceable to ingested documents.
The two tiers use different models deliberately. Workers run on gpt-4o-mini because their job is mechanical: search, retrieve, finish. The orchestrator and a separate synthesis agent use gpt-4o because they need multi-turn reasoning and structured output fidelity. Putting a frontier model on the inner loop of dozens of tool calls per worker would be expensive and unnecessary.
The shared RAG store Link to heading
The connective tissue between parallel workers is a shared RAG service backed by an intercepting MCP toolset. Every web crawl a worker performs is automatically ingested into the shared store before the receipt lands in that worker’s context. Worker B can search for content that Worker A crawled moments earlier — with no coordination code at all. The RAG layer handles it transparently.
This turns out to be a more powerful pattern than passing message history between agents. The shared store is a form of context that persists across agent boundaries without any explicit wiring. The tradeoff is that retrieval is approximate — chunking and embedding can miss exact matches — but workers return cited_node_ids alongside their summaries so the synthesis agent can always expand specific nodes for precision when it needs it.
Context engineering Link to heading
This is where the real work is. Each tier has a completely different context strategy because their lifetimes and failure modes are different.
The orchestrator accumulates history across the entire session. Left unchecked this becomes expensive and eventually exceeds the context window. Before each model call, a history processor fires: once the history exceeds a threshold, everything older than the last few turns gets summarised by a cheap model into a single prose block, and only the recent tail is kept verbatim. The key constraint is that tool-call and tool-result messages must always stay paired — splitting them causes an API error — so the compression finds a safe cut point by walking backward until it lands on a clean message boundary.
Workers have the opposite problem. A single agent.run() call drives the full internal tool-call loop — web search, RAG retrieval, answer synthesis, finish — all without any outer Python loop. The model sees the entire chain of tool calls and results in context as it works. No state injection needed, because the model already has everything.
The interesting case is continuation: what if a worker doesn’t finish in one run? An earlier version of this system re-injected a summary of findings into the continuation prompt — but this turned out to duplicate exactly the information already sitting in the last round’s RAG tool returns. The model was seeing the same evidence twice, as both raw retrieval output and a prose paraphrase of it, with no clear signal about which to trust. The fix was to strip the injection entirely. The continuation prompt just says “keep going, call finish when done.” The last round’s tool results already carry the evidence; there’s nothing else to add.
Insight collection happens once, after all work is complete, by scanning the RAG tool return messages for factual findings. It feeds the synthesis agent and the task log. It has no effect on any context window — it’s observability infrastructure, not context engineering.
The synthesis step Link to heading
Rather than asking the orchestrator to produce a final report while also managing conversation state and potentially re-planning, synthesis is a separate agent with a narrow brief: take the worker summaries and the list of ingested documents, produce a structured report, do nothing else. Keeping planning and synthesis in the same prompt tends to produce outputs that read like they’re still thinking — hedged, half-structured, and prone to adding new tasks at the end.
What this gets right Link to heading
The system treats context as the primary engineering concern rather than an afterthought. Each agent sees exactly what it needs: the orchestrator has compressed long-term memory plus a live recent tail; workers have a clean initial context and, if continued, just the last round; the synthesis agent has summaries and source metadata but no history noise. The shared RAG store handles cross-agent knowledge without any message-passing complexity. And the model tier split keeps costs proportional to the cognitive demand of each task.
The retrieval layer Link to heading
The research system also relies on a structured RAG pipeline designed to stay predictable and cheap even as documents accumulate. Instead of treating documents as flat collections of chunks, ingestion builds a hierarchical index: each document is split into sections and subsections, and every node stores its title, a short preview snippet, and a character span pointing back to the canonical text. That span mapping is important because it allows the system to recover exact evidence later with precise citations.
Document
├── Chapter
│ ├── Section
│ │ ├── Subsection
│ │ └── Subsection
│ └── Section
└── Appendix
Retrieval starts with a deterministic lexical search over these nodes using weighted fields like titles and previews. This produces a ranked list of candidate sections without any model involvement. From there the system builds a small “overview packet” around those candidates — essentially a trimmed map of the document structure containing the relevant branches of the hierarchy. Instead of seeing the document itself, the model sees this navigation map.
The model’s job is not to answer the question yet but to decide where to zoom in. It selects a few nodes to expand, the system loads their children, reranks them lexically again, and the process repeats for a few rounds. In effect the model is navigating the document like a table of contents, progressively drilling down until the relevant sections are identified. Once the search converges, the pipeline extracts the underlying text spans directly from the document and assembles the evidence with section paths and page references. That final extraction step is fully deterministic.
This design trades pure semantic retrieval for structure-aware navigation. Embedding-based systems try to find the most semantically similar chunks anywhere in the document, while this approach assumes that answers usually live inside coherent sections and uses the document hierarchy to guide exploration. In practice this works well for structured material like research papers, reports, and technical documentation, while remaining easy to debug: lexical scores are visible, model decisions are explicit, and the evidence always traces back to exact text spans. If semantic recall becomes important later, embeddings can simply be added as another candidate generator without changing the rest of the pipeline.
In next step I will:
-
Add evaluation layer for this system.
-
Investigate the modern way of interacting with agent system.
-
Integrate vector store in this mixed RAG pipeline and make comparison between pipelines with vectorDB and without vectorDB.
-> Why choose Pydantic AI?
If the goal is to build a multi-agent system that actually behaves predictably, the framework matters. I chose Pydantic AI mainly because it treats agents as typed programs rather than prompt scripts. Tools, inputs, and outputs are defined with Pydantic models, which means the model is guided toward structured responses and failures are caught early instead of leaking into downstream steps. In a system with orchestrators, workers, RAG tools, and synthesis agents all talking to each other, that kind of type safety and validation becomes extremely valuable.
Just as importantly, Pydantic AI exposes the full tool-call loop in a way that fits well with agent workflows. A single agent.run() can drive multiple tool calls internally — search, retrieval, reasoning, and finishing — without needing a custom control loop around every step. Combined with first-class support for tool schemas and structured outputs, it makes it straightforward to build agents that are composable, observable, and relatively easy to debug.
In practice this means less time fighting prompt formatting or fragile parsing logic, and more time focusing on the actual system design — orchestration, retrieval, and context engineering.