Projects
Dive into some fun projects I’ve done!
LLM System Optimization and Edge Deployment Link to heading
Accelerated Inference for Open-Source LLMs on resource limited device
Powerful LLMs should not be confined to data centers. To truly democratize AI, they must run efficiently on everyday hardware. This project focuses on optimizing inference speed, reducing memory overhead, and enabling deployment on edge devices, bringing AI closer to real-world accessibility. I am a fan of small LLM and sparse LLM.
Major trials
-
Engineered low-level optimizations such as KV cache management and rotating context windows to reduce memory overhead and improve inference speed.
-
Applied model compression techniques (quantization, pruning) to shrink model size while retaining accuracy.
-
Accelerated inference on consumer-grade and edge hardware, improving responsiveness and enabling offline/low-bandwidth usage scenarios.
Technologies: C/C++, Python, LLM inference, model compression.
More to read regarding LLM inference LLMsys, LLM compression, kv cache and myprune designed by myself.
AI-Powered Systems for Real-World Applications Link to heading
Since the release of ChatGPT, I’ve been fascinated by how a probabilistic model, trained simply to predict the next token, can exhibit reasoning and communication skills that resemble human intelligence. This sparked my curiosity about the nature of intelligence itself and how such models might reshape the way we live and work. Driven by this wonder, I’ve devoted myself to exploring how AI can be integrated into real-world systems, automating workflows, augmenting creativity, and ultimately freeing humans to focus on higher-level pursuits.
I realize that there is a long way to go, to fully unlash the potential of AI. More data, more training hours and more sophistic models are definitely valuable, while good context engineering is crucial to LLM’s performance on specific tasks. I will continurously share my exploration with AI as a helpful tool at this repo.
What I have done along the way
-
Built LLM-powered applications including a chatbot and VS Code plugin full-stack pipelines, with a focus on integrating advanced Retrieval-Augmented Generation (RAG) to ground responses in external knowledge bases, enabling more accurate, context-aware outputs.
-
Facilitated LLM with tools such as web browsing, pdf ingestion, third party api calls to build an AI Agent that automates workflow with little human interference.
-
Expanded beyond text by incorporating Speech-to-Text (ASR) and Text-to-Speech (TTS) models, creating a seamless multi-modal conversational system.
-
Finetuned LLM on downstream tasks, delivered an end-to-end product experience from ideation to deployment, demonstrating strong skills across architecture, integration, and user experience.
Technologies: Python, js/ts, LLM full stack dev, model ingeration and deployment.
Lidar Panoptic Segmentation Link to heading
A combination of semantic segmentation and multi-object tracking
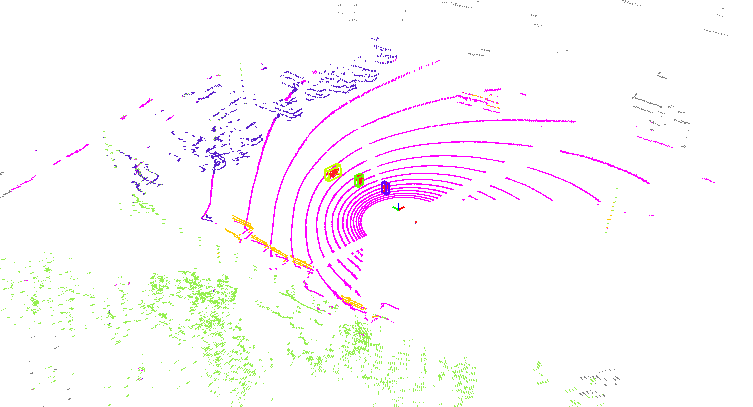
This project was a crucial part of advancing autonomous driving technology for construction vehicles at Volvo Construction Equipment. Reliable perception is a prerequisite for safety in these environments, and I focused on improving a vehicle’s ability to understand its surroundings in 3D and over time. My work delivered a complete pipeline for 4D panoptic segmentation, with a focus on hyperparameter optimization, to accurately identify and track objects like other people and machines, which is vital for collision avoidance.
Key Contributions
-
Developed and optimized a state-of-the-art perception pipeline for autonomous construction vehicles, by adapting and training an advanced 4D LiDAR panoptic segmentation model to the specific challenges of the Volvo dataset, enhancing its ability to understand complex scenes.
-
Engineered robust data pipelines on a Linux platform to efficiently manage and process large-scale 3D point cloud data from LiDAR sensors, ensuring a clean and reliable data flow for deep learning model training.
-
Maximized model performance through automated hyperparameter optimization using Bayesian optimization with PyTorch. This approach significantly improved the training speed and model’s accuracy, a crucial factor for ensuring safety in real-world scenarios.
Technologies: Deep learning, hyperparameter optimization, scene understanding, data pipeline construction.
More to read my thesis
GPS and IMU Sensor Fusion Link to heading
How to combine data from different sensors, each with its own strengths and weaknesses, to achieve a more accurate and reliable understanding of a system’s position and movement. Sensor fusion to merge data from a Global Positioning System (GPS) and an Inertial Measurement Unit (IMU) is crucial for applications like self-driving cars and robotics.
Key takeaways
-
Implemented a robust sensor fusion system to enhance the localization accuracy of autonomous platforms by combining data from GPS and IMU sensors.
-
Applied advanced state estimation theory by deriving and implementing Kalman Filter and Error-State Kalman Filter algorithms to model and estimate motion under uncertainty.
Technologies: Python, state estimation, Kalman Filter.
More to read study report, for a quick grasp of the math under the hood, refer to my blogs related to Kalman Filter and Error state Kalman Filter
Pedestrian Attribute Recognition and re-identification Link to heading

Example from Market1501 dataset
A crucial task in computer vision for applications like surveillance and human-robot interaction. It involves teaching a model to identify specific characteristics of a person, such as their clothing or gender, from an image. This work aimed to build a robust deep learning pipeline to accurately identify these attributes, which can be combined with re-identification (ReID) systems to track individuals across different camera views.
Key takeaways
-
Engineered a deep learning pipeline in PyTorch for pedestrian attribute recognition, with a focus on optimizing model performance and training workflows.
-
Boosted model accuracy by enhancing a ResNet50 convolutional neural network with custom attention modules, allowing the model to focus on the most relevant features and ignore noise.
-
Utilized Python and the Pandas library to create a streamlined data workflow for efficient preprocessing and postprocessing of image datasets.
Technologies: Python, Pytorch, deep learning.
More to read study report
Point Cloud Registration Link to heading
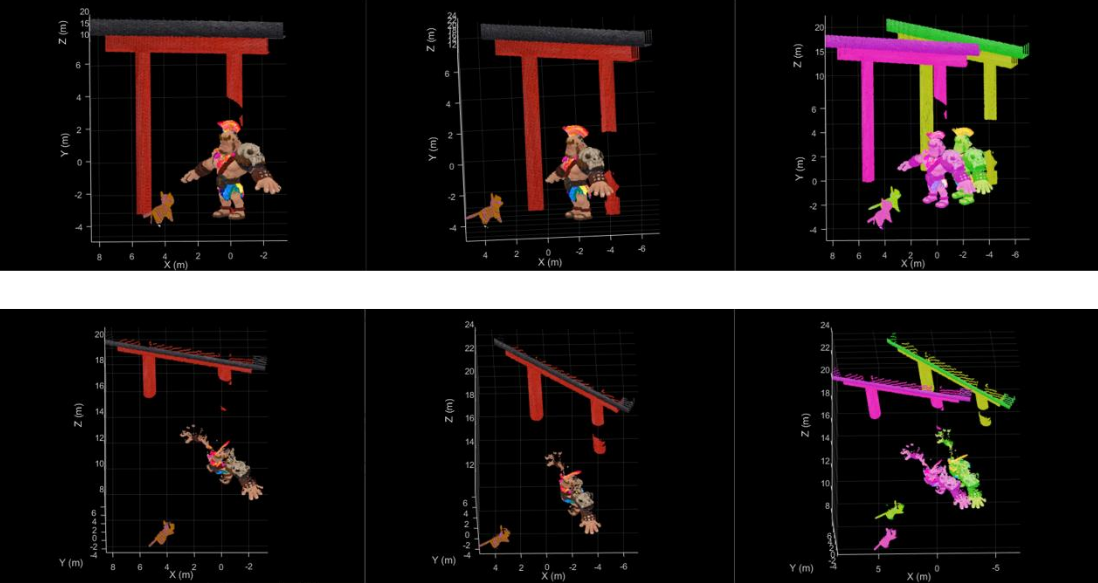
Bringing Physical Objects to the Digital World
How do we teach a computer to see and understand the world in 3D? By using multiple 3D scans of a physical object, my team and I developed a robust C++ pipeline to align and stitch them together, creating a unified digital model. This process is crucial for applications ranging from robotics and autonomous vehicles to augmented reality.
Key takeaways
-
Engineered a multi-stage 3D point cloud registration pipeline in C++, encompassing data preprocessing, feature extraction, and coarse-to-fine registration.
-
Implemented and evaluated various keypoint detection and descriptor algorithms, including ISS3D and SIFT3D, to identify unique geometric features in complex point cloud data.
-
Developed and applied advanced registration techniques, leveraging Sample Consensus Initial Alignment (SAC-IA) for robust coarse alignment and Iterative Closest Point (ICP) for precise, fine registration.
-
Confronted real-world data challenges by incorporating noise filtering, down-sampling, and outlier removal to ensure the accuracy and reliability of the reconstruction process.
-
Utilized the Point Cloud Library (PCL) and Open3D as core frameworks to efficiently manage and process large-scale 3D datasets.
Technologies: C++, Linear Algebra.
More to read study report